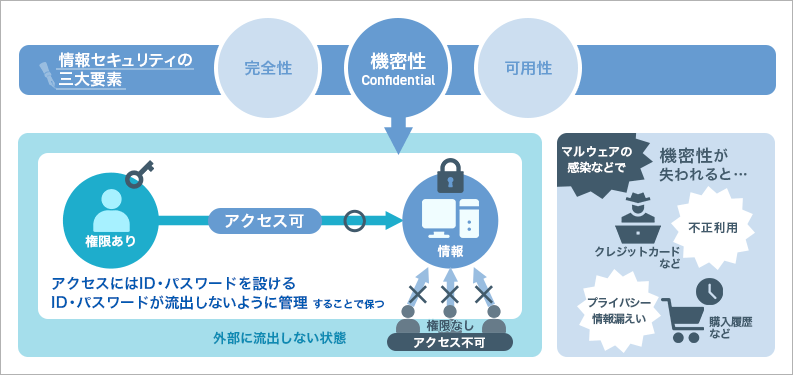
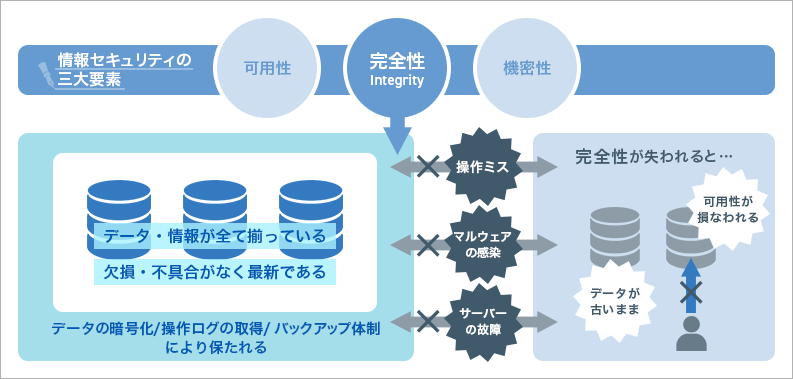
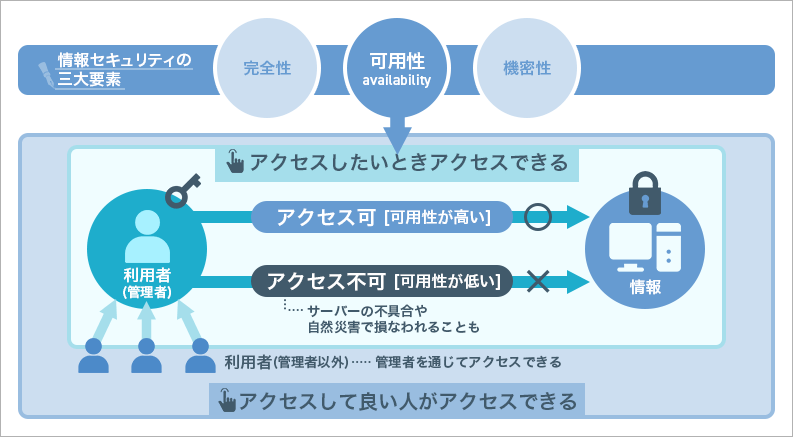
非機能要件
業務要件の定義で明確にした業務要件を実現するために必要なシステムの機能要件以外の要件
使用性
ITシステムの使用性とは、そのITシステムの機能が使いやすさを意味しています。
例えば何の説明もなくても、そのITシステムを使うことができれば、使用性の高いITシステムだということができます。あるいは、2~3時間の研修を受けただけで、十分に使いこなせるようになるのであれば、それも使用性に優れたITシステムです。
この他に、使用するにあたって疑問がでた時に参照するヘルプページを作ったり、誤った操作をした時に正常な操作に戻しやすくするのも使用性の向上につながります。
アンゾフの成長マトリクス
イゴール・アンゾフ(1918-2002)は、「戦略的経営の父」とも呼ばれるロシア系アメリカ人の経営学者です。彼の業績のなかで、最も有名なものが「アンゾフの成長マトリクス」と呼ばれるフレームワークです。
アンゾフは、成長戦略を「製品」と「市場」の2軸におき、それをさらに「既存」と「新規」に分けました

アライアンス
工場を持たず、半導体の規格・開発・販売を行う半導体メーカーのこと。
製造に特化した半導体メーカー。ファブレス企業から受注し利益を上げています。
ファウンドリサービスとは、半導体の生産設備を保有し、他社から半導体の製造を受託する会社です。半導体の製造だけを専門的に行い、自ら回路設計を行うことはしません。
製造プロセスの微細化が進む半導体業界では、会社ごとに工場を持ってその都度対応するための投資を続けるより、他社に製造委託してしまった方が結果的にコストを抑えることができるため、このような垂直分業が発展しています。
自社で設計・製造・組み立て・検査・販売まで全て一貫して行う半導体メーカー。
かんばん方式とは、必要なものを、必要なときに、必要なだけ作ることを目的として、タスク管理や進捗管理を効果的に行うためにトヨタ自動車が開発した生産管理の方法です。
製造する商品には「かんばん」と呼ばれる商品管理カードがあり、商品名・品番・保管場所など詳細な情報が書かれています。
そして、このかんばんの指示通りに生産することで無駄がなくなり、その後の工程もかんばんを確認することで詳細を把握できるという仕組みです。
かんばん方式は、製造業の生産工程の管理だけでなくさまざまな業界でのプロジェクト管理にも取り入れられています。
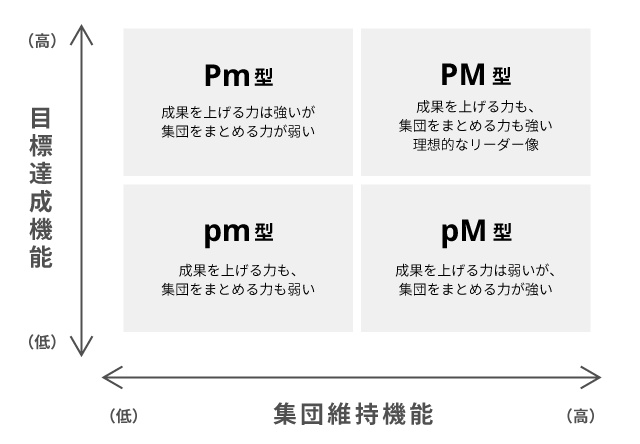
PM理論
PM理論とは、リーダーに必要な要素は「目標達成のP機能」と「集団維持のM機能」の2つで、さらにそれぞれを強弱に分類した4パターンであるとする理論のこと。
PM理論は別名「パパママ理論」とも呼ばれています。これはP機能に目標達成して成果を挙げるための厳しい「パパ」の働きを、M機能にチームをまとめる優しさや包容力などの「ママ」の動きをなぞらえたものです。
パパのような厳しさで目標を達成させ、ママのような優しさでチームをまとめる人物こそが、理想的なリーダー像であると唱えています。
SL理論
SL理論とは、「Situational Leadership」のことを指しており、状況に対応したリーダーシップを意味しています。1977年に行動科学者であるポール・ハーシーと組織心理学者のケネス・ブランチャードによって提唱された理論です。
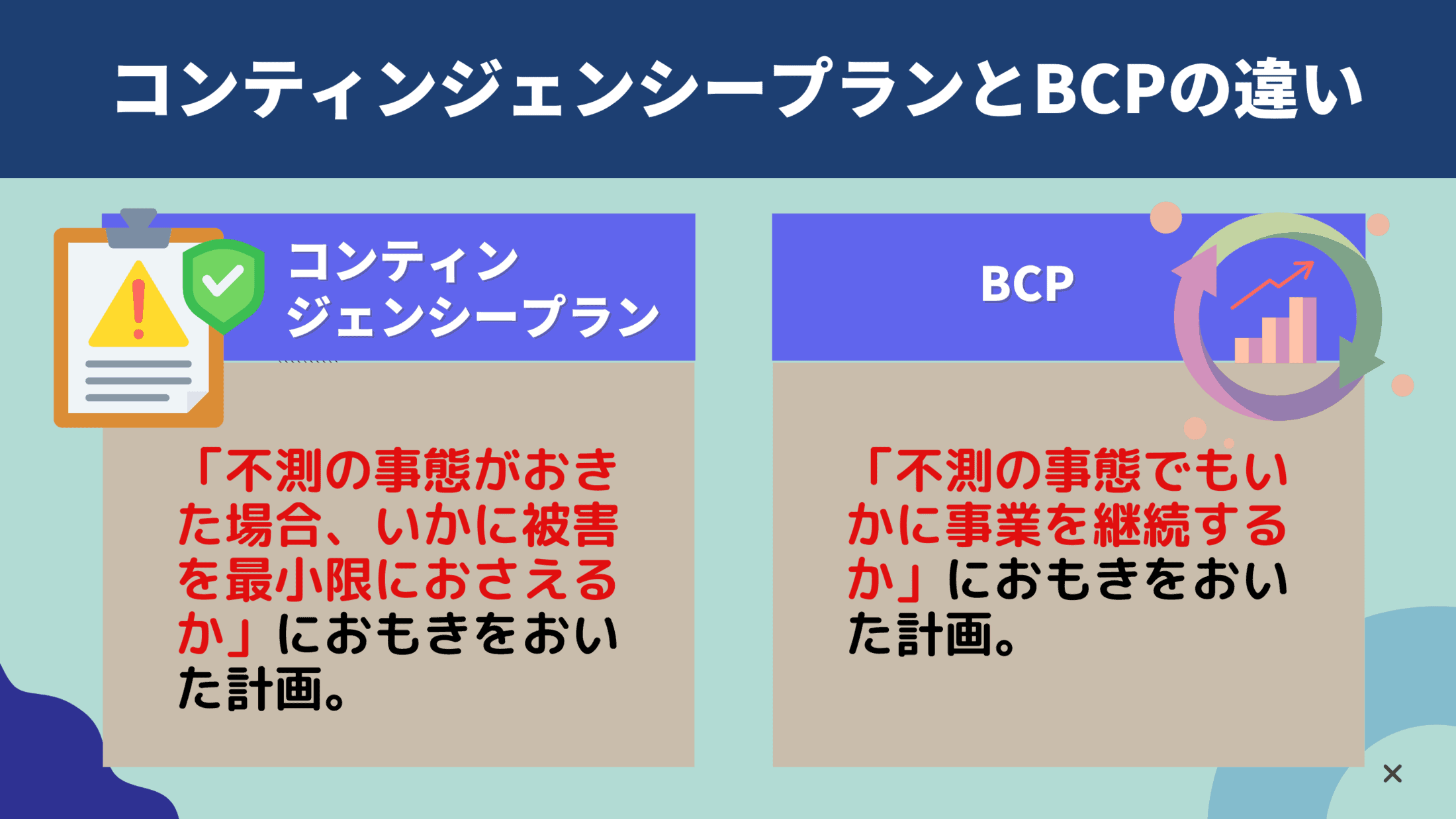
SL理論が提唱される以前には、F・フィドラーが提唱したコンティンジェンシー理論というものがありましたが、すべての状況に適応できる唯一最善の普遍的なリーダーシップやスタイルは存在しないという考えが基本になっていました。
リーダーはその資質が重要というよりも、状況に応じて役割を柔軟に変えていく必要があるという考え方です。
SL理論はコンティンジェンシー理論をさらに深く掘り下げて、部下の成熟度という観点から発展させた理論だといえます。
SL理論は、部下の状況に合わせて活用するのがポイントです。SL理論が有効に働く組織は、「リーダーシップの型が決まっている」「部下の育成能力が低い」などの課題を抱えているケースが多い傾向にあります。
リーダーの役割が固定化されている組織においては、状況に応じてリーダーシップの型を変えるようにしたほうが望ましいため、SL理論が有効に働く可能性があります。SL理論は部下の能力や意欲によって、4つの成熟度に分類します。
RoHS指令「Restriction of the use of certain Hazardous Substances in electrical and electronic equipment」
私たちの生活を豊かにする、携帯電話やパソコン、冷蔵庫や空調機器、さらには自動車。
これらの製品は様々な素材から造られています。この中には、化学反応を起こして作られた化学物質も入っています。化学物質は危険性が低い物も多数ありますが、その一方で人の健康を害するものや環境に悪影響を及ぼす物質もあります。この危険性のある化学物質による人の健康や環境への悪影響を抑えるため、各国で特定の化学物質への規制が行われ、その対象は薬剤などの化学品や完成品の商品にまで広がっています。
中でも、欧州連合(EU)各国では、廃電気・廃電子機器の約90%が正しい処理を経ずに埋立てや焼却されており、化学物質が地下水へ浸出することによる環境汚染、また人体への悪影響が問題となっています。このため、EUでは「RoHS指令」という電気・電子機器における特定有害物質の使用制限に関する法律が2003年2月13日に告示され、2006年7月1日から施行されました。このRoHSは2011年に大幅に改正され2011年6月1日に告示、2013年1月3日から現在に至るまで施行されています。(当初のRoHS規制はRoHS2規制の施行とともに2013年1月廃止されています。)
オプトイン、オプトアウト
「オプトイン」と「オプトアウト」は、それぞれ英語の“opt in”と“opt out”を語源としています。“opt”とは(自)動詞で、“選ぶ”とか“決める”という意味があります。そして、“in”と“out”は、その名の通り“入る”とか“出る”という意味があります。ここまでは、英語の復習。
つまり、「オプトイン」とは、活動や団体に対して“参加する”とか“加入する”という意味合いを持つ言葉です。それに対して「オプトアウト」は、“不参加”とか“脱退する”という意味合いになります。そのことをメールに関係付けて、もう少し分かりやすく図を使って説明しましょう。
まず、オプトアウトという仕組みは、メールの送信は原則自由で、受け取りたくない受信者は個別に受信拒否通知をする形になります。つまり、受信者が、メールが届いたあとに“opt out”の手続きをすることでメールの受信を拒否するわけですね。
それに対して「オプトイン」は、受信者となる人が事前に送信者に対してメール送信に対する同意を与える、もしくは依頼するという形になります。つまり、受信者が参加の意思表示を“opt in”の手続きによって行うことによって初めて、送信者はメールを送ることができるわけです。
この二つの仕組みで一番重要なのは、「主導権がどちらにあるか」ということです。オプトアウト方式ではメールの送信者側に主導権があり、オプトインではメールの受信者側に主導権があるということに注目してください。
オプトアウト方式では、受信者が出来ることは受信拒否手続きなどに限定されていましたが、オプトイン方式では受信者がメールを受信するにあたり事前にその趣旨や内容を吟味できることになります。極端な話、受信者が「メールを送っていいですよ」と言わなければメールが届くことはありません。また、身に覚えのないメールに対して苦情が言いやすくなっています。
日本国内では、平成20年12月1日に施行されたた迷惑メール対策関連の改正法により、広告・宣伝メールなどの送信が、それまでのオプトアウト方式からオプトイン方式に変更されました。
ECサイトや配信事業などで、ユーザーに対して商品やサービスをおすすめするサービスが「レコメンデーション」です。レコメンデーションの手法のひとつとして、協調フィルタリングは広まりました。従来のレコメンド機能は、あらかじめ設定した商品やサービスがユーザーの属性に関係なく表示される仕組みでしたが、ユーザーの需要を的確に満たせない欠点がありました。そのためパーソナライズされた情報を提示できる、協調フィルタリングに注目が集まったのです。
レコメンデーションに協調フィルタリングを用いることで、システムはあるユーザーの消費活動と、別のユーザーのデータを照会できます。そして、お互いの行動を関連づけ、個人の需要を予想して商品やサービスを薦められます。協調フィルタリングはアイテム同士を結びつけているのではなく、複数の個人データを分析するのが特徴です。つまり、ユーザーが「欲しいのに持っていないもの」や「知らなかった意外なもの」を訴求できる強みを備えています。ただし、購入履歴の少ない商品はレコメンドできないのが協調フィルタリングのデメリットです。
内容ベースフィルタリングと何が違う?
レコメンデーションで使われる手法として、「内容ベースフィルタリング」も挙げられます。内容ベースフィルタリングはユーザーが購入した商品のタグ情報から、レコメンドするアイテムを選定します。ユーザーの興味がある分野をしっかりと把握することを目的としているので、ユーザーの趣味・嗜好(しこう)を高確率で押さえられ、類似商品をおすすめできるのがメリットです。しかし、タグをすべての商品に設ける手間が発生してしまうデメリットがあります。
協調フィルタリングとの最大の違いは、何を基準としてレコメンド商品を選んでいるかです。協調フィルタリングがユーザー同士の購買履歴を分析するのに対し、内容ベースフィルタリングはあくまでタグを基準にしています。購入履歴の少ない商品を訴求したいなら内容ベースフィルタリング、ユーザーの消費傾向を細かく踏まえたいなら協調フィルタリングが適しています。
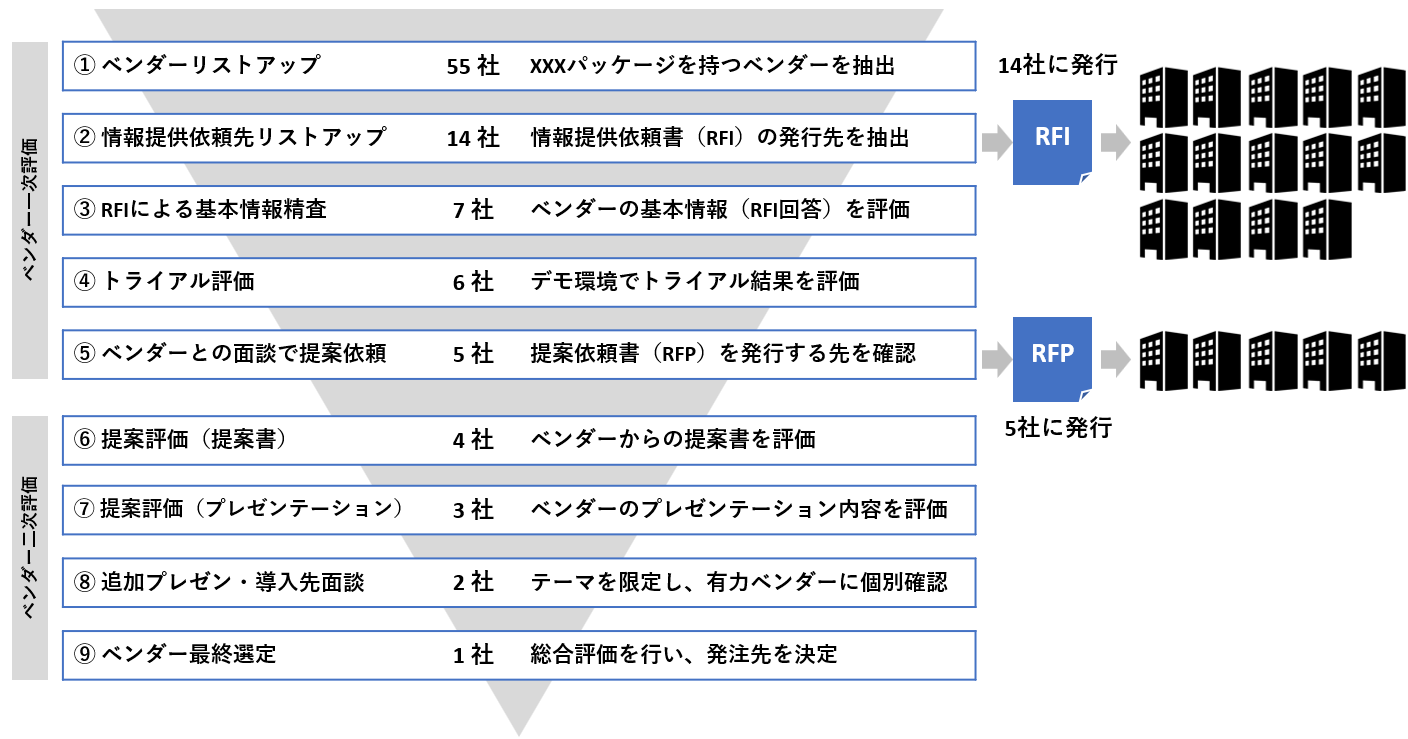
RFIは、Request For Informationの略で、情報提供依頼書
RFPは、Request For Proposalの略で、提案依頼書
どちらもベンダーに依頼する書類ですが、依頼する内容が異なります。
RFIは「情報」を要求します。持っている情報を特に加工せず「ありのまま下さい」と要求します。RFIの内容は、基本的な質問事項が並ぶことになります。
そのため、回答するベンダーは負担が少なく、回答してもらいやすくなります。自社のシステム化要求には触れずに「一方通行」でベンダーの情報をもらう形となります。
一方でRFPは、「提案」を要求します。そのためには、自社のシステム化要求をベンダーに伝え、自社に合った提案書を受け取る必要があります。そのため、RFPではシステム化要求を細かく定義します。自社の業務内容をきちんと開示し、プロジェクトのスケジュールや進め方、契約内容などの要求も記載します。
RFPは、自社の情報を渡して、ベンダーから提案をもらう。つまり「双方向」の形となります。
まとめると、RFIとRFPはベンダーに渡す「タイミング」と対象とするベンダーの「数」が違います。
まずRFIで「広く浅く」多くのベンダーに情報を求めます(図の例では14社)。次にRFPで「狭く深く」で絞ったベンダーに提案を求めます(図の例では5社)。RFIとRFPを効果的に活用することで、選定の質を大幅に引き上げていくことができます。
イノベーター理論を語る上で欠かせないキャズム理論
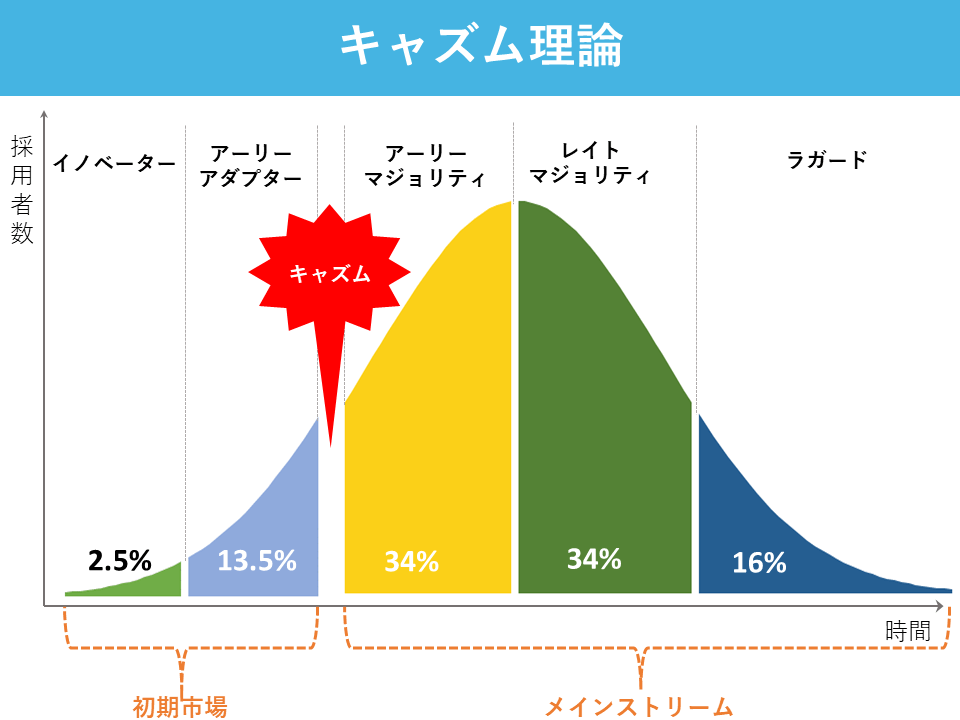
「商品普及の鍵はアーリーアダプターが握る」という説に対して一石を投じたのが、アメリカのマーケティング・コンサルタントであるジェフリー・ムーア氏です。彼は、著書『キャズム』(翔泳社刊)の中で、市場に商品が普及していく際に問題となる大きな溝(キャズム)について提言しました。これをキャズム理論と呼んでいます。
ここからは、キャズム理論の概要と発生する原因について順番に解説します。
キャズム理論とは、初期市場(イノベーター・アーリーアダプター)とメインストリーム市場(アーリーマジョリティ・レイトマジョリティ)の間にはキャズムと呼ばれる大きな溝が存在しており、このキャズムを乗り超えられない限り、新しい商品はメインストリーム市場で普及することなく、小規模な初期市場の中でやがて消えていく運命を辿るとする理論のことです。
主にハイテク業界で頻繁に取り上げられる話題であり、新規事業の立ち上げを成功させるポイントの1つとされています。
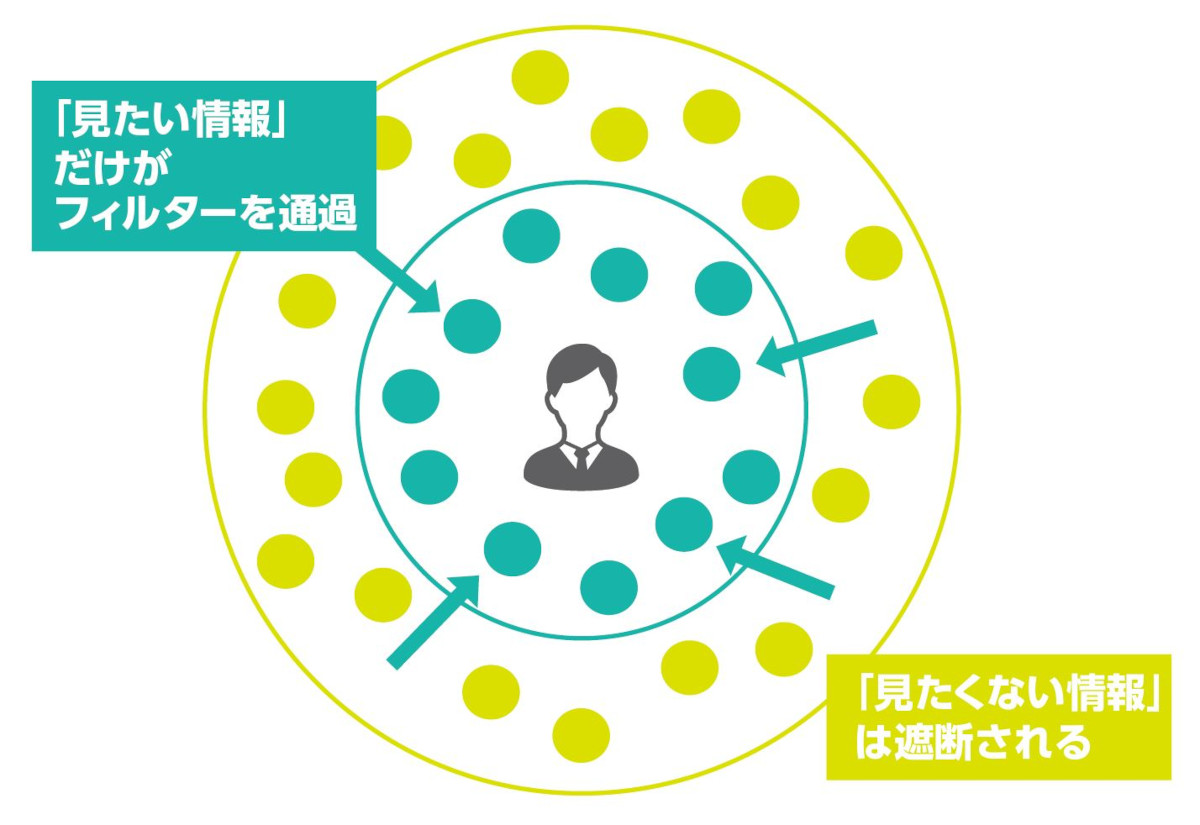
フィルターバブル
アルゴリズムがネット利用者個人の検索履歴やクリック履歴を分析し学習することで、個々のユーザーにとっては望むと望まざるとにかかわらず見たい情報が優先的に表示され、利用者の観点に合わない情報からは隔離され、自身の考え方や価値観の「バブル(泡)」の中に孤立するという情報環境を指す。
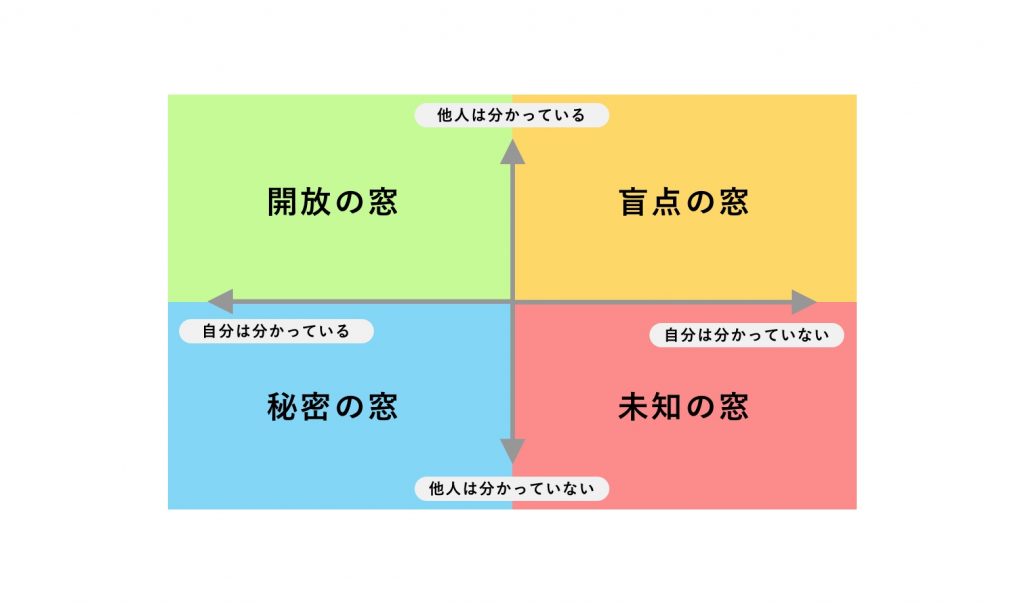
ジョハリの窓は、自己分析をしながら他者との関係を知ってコミュニケーションを模索する心理学モデルとして生まれました。ジョハリの窓はもともと1955年にアメリカで開催された「グループ成長のためのラボラトリートレーニング」の席上で「対人関係における気づきのグラフモデル」として発表されたものです。
主観と客観の両面から自分自身を認識するための自己分析ツール
ジョハリの窓とは、自分と他人の認識のズレを理解する自己分析ツールです。自分の性格は自分が一番知っていると思い込んでいる人も多いでしょう。しかし実際は自分のことゆえに見えない性格なども多いのです。
ジョハリの窓は他者と自分の関係から自己分析、自己への気づきを促し、人間関係やコミュニケーションの円滑な進め方を模索するために作られました。
営業活動によるキャッシュ・フローは、「本業で稼いだお金」をあらわしています。つまり企業の営業活動によって流入、流出した現金の動きです。
たとえば、「商品を販売して稼いだ現金」「材料を仕入れるために支払った現金」「広告宣伝費などの支払いの際に流出した現金」などが該当するほか、税金の支払い、災害に伴う保険金の受取など100%本業のお金の動きといえないものも、すべて営業活動に区分されます
投資活動によるキャッシュ・フローでは、会社がどれだけ会社を成長させるために投資しているかを表します。
新たに設備を購入するなどの投資を行えばマイナスになり、設備を売却すればプラスとなります。成長に向けて積極的に投資を続けている会社であれば、通常は投資活動によるキャッシュ・フローはマイナスとなります。
したがって、投資活動によるキャッシュ・フローのマイナスは、決して悪いことではありません。会社を成長させるためには、新たな設備の導入は必要な支出といえるからです。
投資を行わない企業は、現状維持のまま終わってしまいます。そのため、基本的に会社は投資をする必要があります。
財務活動によるキャッシュ・フローでは、会社がどのように資金を調達したのかが分かります。
財務活動によるキャッシュ・フローは、資金調達をして現金預金が増えればプラス、減ったらマイナスです。
本業で稼いだお金は、営業活動によるキャッシュ・フローに区分され、借入れや投資家からの出資など、本業以外でお金を得た場合には、この財務活動によるキャッシュ・フローに区分されます。
財務活動によるキャッシュ・フローは、以下のように分けて記載されます。
「契約書」は何のために作るのか
従来は紙で行っていた契約を、電子文書で取り交わすものを「電子契約」と呼びます。したがって、電子契約について考える際には、法的に有効であるかがポイントとなります。
まずは「契約書」が何のためにあるのか、解説しましょう。
「契約」は口頭でも成立します。口約束でも成立するのです。契約書は契約の要件ではありません。
しかし、契約について争いが起こったときには、その契約を証明しなくてはならず、口頭での契約では証拠が存在しません。こういった場合に備え、証拠とするために契約書が必要となるのです。
契約書は、特に訴訟において「契約の証拠になるもの」と認識してください。一定の制限はありますが、電子文書による電子契約でも成立します。
紙の文書と電子文書の扱われ方
紙の文書と電子文書の扱われ方についてお話しましょう。法律上では「書面」とある場合、木の板や石版といった有形物であればなんでもよいのですが、一般的には紙で作成します。
法律上で電子文書を表す「電磁的記録」は書面とは認められていませんが、書面が求められていても、電磁的記録を書面とみなす規定があれば問題ありません。
例えば、保証契約では民法446条2項に「保証契約は、書面でしなければ、その効力を生じない」とあります。これは、平成17年の改正によって書面が必要になったものですが、電磁的記録でも認められます。同条3項にて「保証契約がその内容を記録した電磁的記録によってされたときは、その保証契約は、書面によってされたものとみなして」と規定されたためです。
裁判での証拠能力と「真正な成立の推定」
民事訴訟において、文書の証拠を提出するときは、民事訴訟法第228条1項で「その成立が真正であることを証明しなければならない」とあります。では「成立が真正であること」について検討してみましょう。
まず、私が「1,000万円を借りました」と、書面である借用書に名前を書いたとします。そして、貸した側からお金を返せと請求されます。この借用書を実際に私が書いたのであれば請求できますが、誰が書いたのかわからない場合は請求できません。
したがって、誰の意思が借用書や契約書に記されているのか、そして誰が作ったのかを明らかにすることこそが「成立が真正であること」の証明にあたるのです。
しかし、この証明は難しいため、「推定規定」というものもあります。
民事訴訟法228条4項に「本人又はその代理人の署名又は押印があるときは、真正に成立したものと推定する」とあります。すなわち、署名もしくは押印が「成立が真正であること」の推定のための要件となっているのです。
ここでの「本人の押印」とは、例えば私であれば「宮内」という押印がありさえすれば真正とみなされる、というものではなく、それが私のものであることまで証明する必要があります。実印であればこの印鑑が本人のものであると証明できますが、三文判などを使うと本人証明が難しいこともあります。
紙の文書と同じように、電子文書でも「成立が真正であること」を推定する条項が電子署名法第3条にあります。本人による「電子署名」が行われている場合、真正とみなされるのです。本人による電子署名であることは、電子証明書を用いて証明します。
要するに、電子署名は押印と同じ効力を持っています。一定の条件を満たす必要がありますが、証拠として使うことができるのです。
グリーン購入基本原則
1.「必要性の考慮」
購入する前に必要性を十分に考える
2.「製品・サービスのライフサイクルの考慮」
資源採取から廃棄までの製品ライフサイクルにおける多様な環境面や社会面の影響を考慮して購入する
2-1有害化学物質等の削減の削減
環境や人の健康に影響を与えるような物質の使用や排出が削減されていること
2-2 省資源・省エネルギー
資源やエネルギーの消費が少ないこと
2-3 天然資源の持続可能な利用
天然資源の持続可能な利用を図っていること
2-4 長期使用性
長期間の使用が可能であること
2-5 再使用可能性
再使用が可能であること
2-6 リサイクル可能性
リサイクルが可能であること
2-7 再生材料等の利用
再生材料や再使用部品を利用していること
2-8 処理・処分の容易性
廃棄時に適正な処理・処分が容易なこと
2-9 社会面の配慮
社会面に配慮していること
3.「事業者の取り組みの考慮」
環境負荷の低減と社会的責任の遂行に努める事業者から製品やサービスを優先して購入する
3-1 環境マネジメントシステムの導入
組織的に環境改善に取り組む仕組みがあること
3-2 環境への取り組み内容
省資源、省エネルギー、化学物質の管理・削減、グリーン購入、廃棄物の削減などに取り組んでいること
3-3 情報の公開
環境情報や社会的取り組みを積極的に公開していること
4.「情報の入手・活用」
製品・サービスや事業者に関する環境面や社会面の情報を積極的に入手・活用して購入する
バリューチェーン(Value Chain)とは元々、アメリカの高名な経営学者で、ハーバード大学経営大学院教授のポーターが提唱した考え方です。原材料の調達に始まり、商品の製造・出荷・販売・サービスといったビジネスの流れを、「価値の連鎖」として分析し、各セクションを経て加わる価値に着目しています。
バリューチェーンのフレームワークについて解説します。事業活動を大きく「主活動」と「支援活動」の2つに分類し、これらに対し、「利益(マージン)」を紐づけてフレームワークに落とし込むと、自社のビジネスを視覚的に整理できます。
「主活動」とは、ビジネスにおける生産から消費までの流れに関わる活動のこと。主に、商品の製造・開発やサービスの提供などを指します。例えば、製造業の場合を考えてみましょう。ビジネスの流れを整理すると、「購買物流」「製造」「出荷物流」「販売・マーケティング」「サービス」が主活動として考えられます。
一方、生産から消費までの流れに直接関わらない活動を「支援活動」として、主活動をサポートする活動として説明されます。よく挙げられるセクションとしては、「全般管理」「人事・労務管理」「技術開発」「調達」などです。
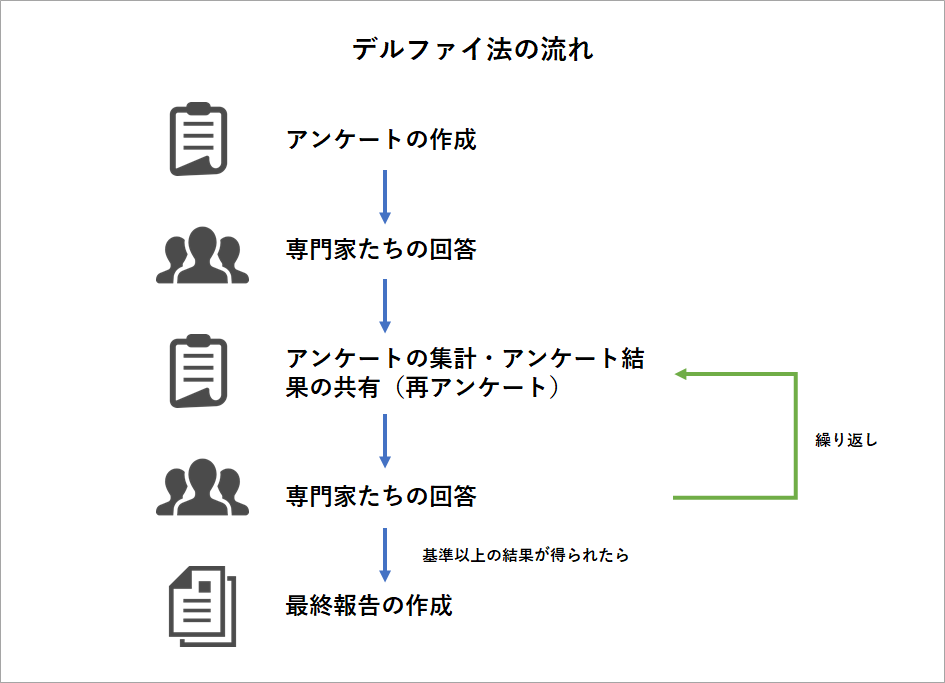
デルファイ
デルファイ法(Delphi法)とは予測技法の1つであり、専門的知識や経験を有する複数人にアンケート調査を行い、その結果を互いに参照した上で回答を繰り返して、集団としての意見を収束させていく方法です。
デルファイ法はプロジェクトマネジメントの中でも見積作成やリスク識別など、さまざまな場面で使用できる手法です。
パテントプール
特許権を持つ複数の企業が、それぞれの特許を持ち寄って共同管理する団体のこと。特許技術を使いたい企業とのライセンス交渉などを一括して進める。標準規格を満たす製品をつくるのに必須となる標準必須特許(SEP)に関して設置されることが多い。通信特許を扱うアバンシはその代表格で、米国に拠点を置いて通信や電機の大手が参加する。

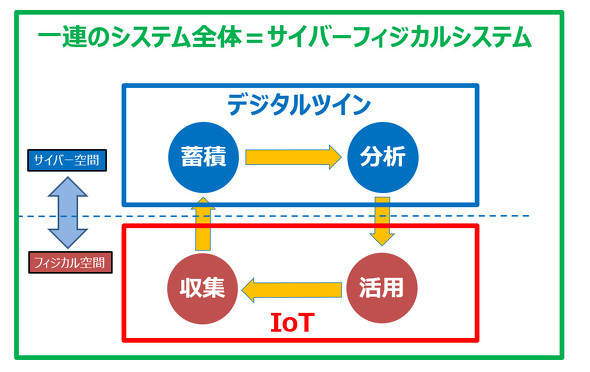
サイバーフィジカルシステム(CPS)
「サイバーフィジカルシステム」とは、現実(フィジカル)の情報を、コンピュータによる仮想空間(サイバー)に取り込み、コンピューティングパワーによる分析を行った上でそれをフィードバックし、現実の世界に最適な結果を導き出すという、サイバー空間とフィジカル空間がより緊密に連携するシステムのことです。
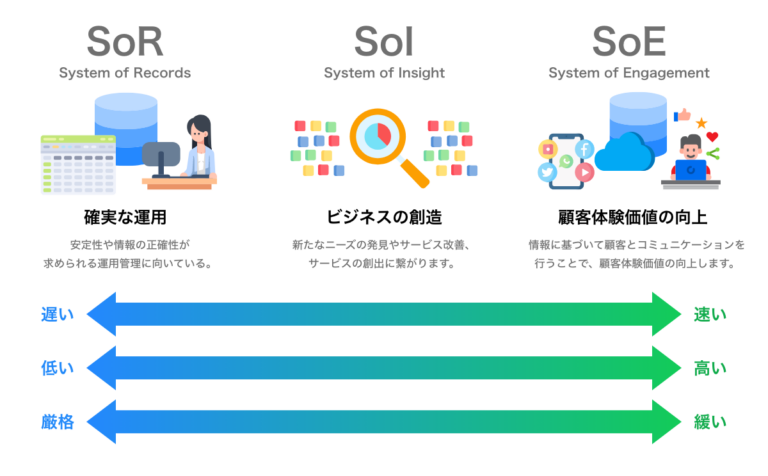
SoE は「 System of Engagement 」の略称で、「エンゲージメントのためのシステム」という意味になります。マーケティングにおいて「エンゲージメント」とは、顧客とのつながりのことを指し、SoE はユーザーとの関係を強化することを目的としています。
従来の IT システムである SoR が企業における業務遂行が主な目的であったのに対して、顧客にとって使いやすく設計されたシステムが SoE であると言えます。また、SoE では顧客のあらゆるデータを収集・分析しながら、新たな需要を見つけたり、ビジネスモデルを創出したりします。
具体的な SoE としては、CRM(顧客関係管理システム)や SNS、グループウェア、レコメンドエンジンなどが挙げられます。
なお、SoE は SoR が発展したものというわけではなく、2 つのシステムは互いにサポートし合う関係にあります。先述の通り、 SoR はあくまで記録を行うための IT システムですが、SoR で得られる正確なデータは顧客との繋がりを創出するために重要だからです。顧客視点を正しく理解するためには、蓄積されたさまざまなデータを活用する必要があるのです。
つまり、顧客との繋がりを作る SoE は、SoR ありきで機能するということです。
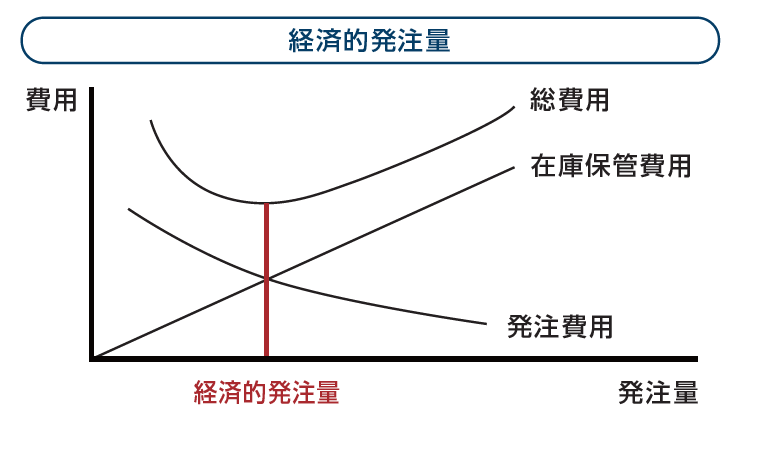
経済的発注量
経済的発注量(英語:Economic Order Quantityまたは頭文字をとってEOQ)とは発注するにあたり、関連するコストの総額を最小化する発注量のことで、経済的ロットサイズと呼ばれることもあります。
わかりやすく言うと、在庫に関するコストが最も少なくなる=経済的な発注量のことです。
発注費用
在庫を保管するための倉庫の土地代や空調などの電力代、人件費など、在庫
を維持するためにかかる費用。在庫量を少なくすることで、削減することが可能。
在庫維持費用
商品や原材料を発注する毎にかかる費用。在庫量を多くすることが
できれば、発注回数を削減し、発注費用の削減に。
この2つの合計が最も小さくなる1回あたりの発注量から導出(導き出す・求める)ことができます。

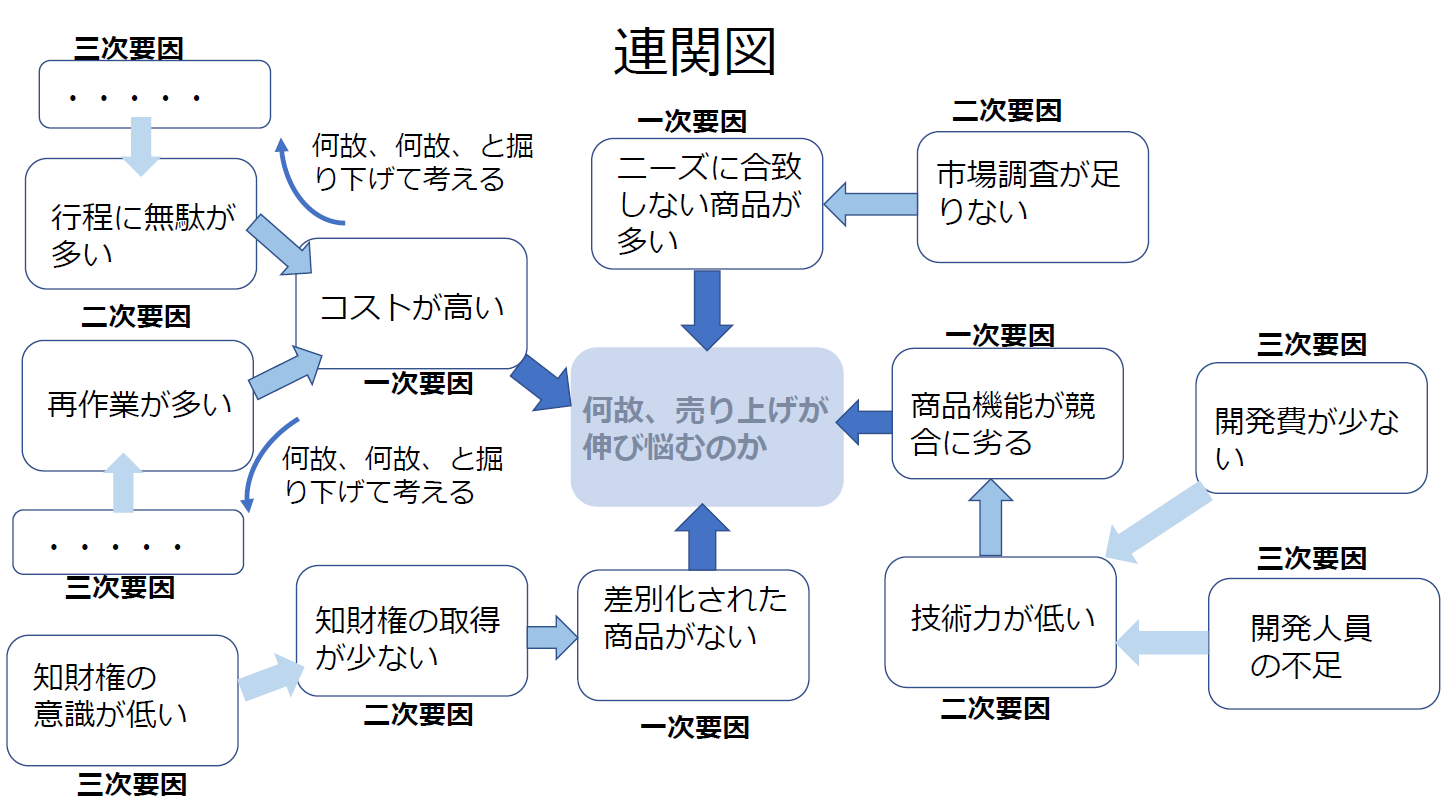
解決すべき問題を端か中央に置き,関係する要因を因果関係に従って矢印でつないで周辺に並べ,問題発生に大きく影響している重要な原因を探る。
系統図法
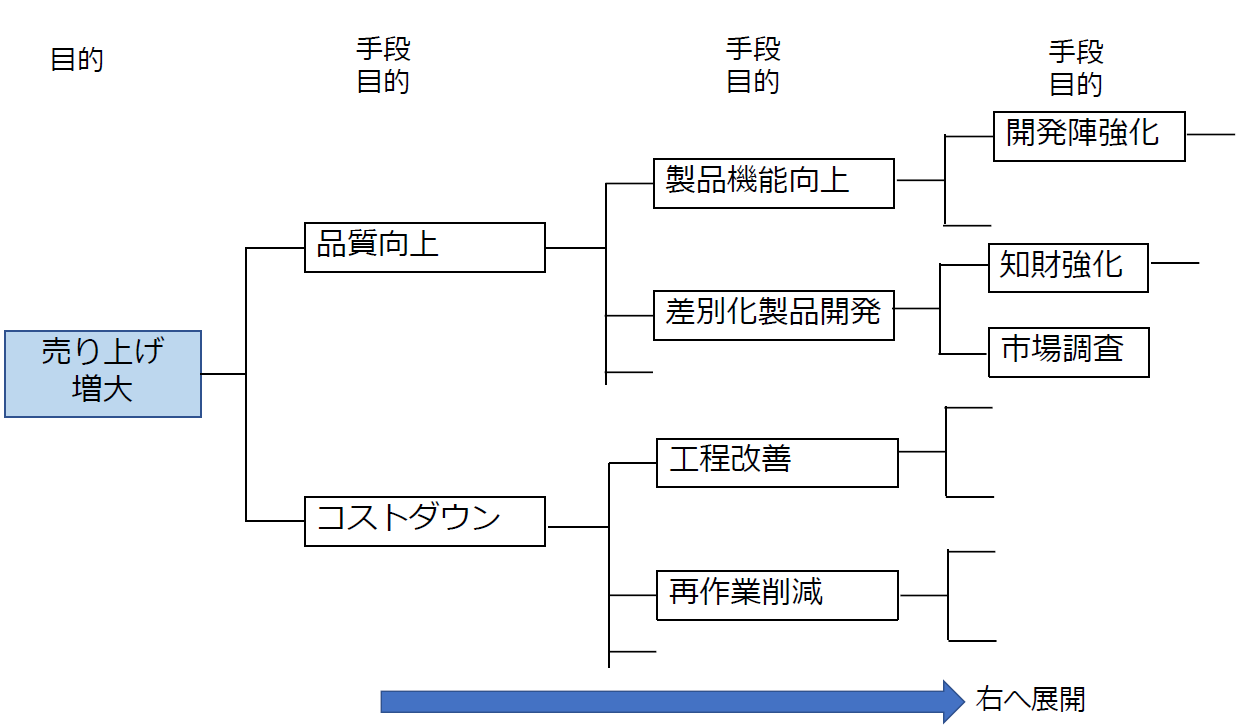
目的を達成するための手段を導き出し,更にその手段を実施するための幾つかの手段を考えることを繰り返し,細分化していく。
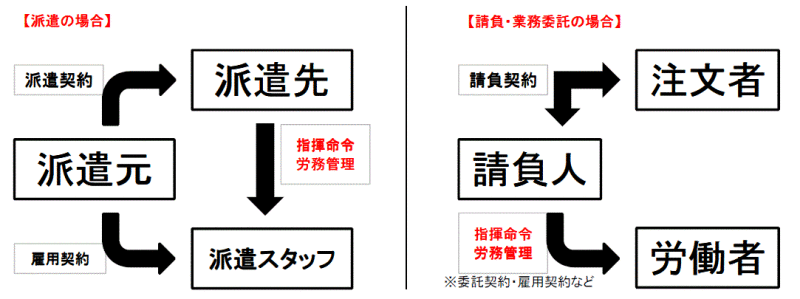
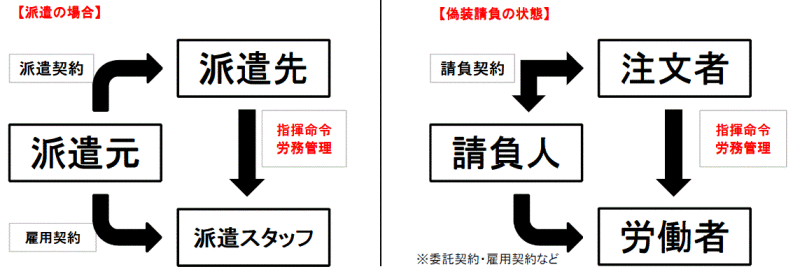
プロバイダはサイトの管理や運営を行いますが、誰が何を投稿するのかまでは管理できません。そのため、不法な投稿をされた場合下の図のようなことが起こってしまう場合があります。

被害者に削除を要求された場合でも、勝手に削除してしまうと、加害者側から『表現の自由を侵害した』と損害賠償請求をされてしまう可能性もあるのです。
このような板挟みの状態になってしまうのを避けるためにあるのが『責任制限』です。一定の条件と引き換えにプロバイダに対する損害賠償請求を阻止できます。
では、損害賠償の請求ができる場合はどのようなものなのでしょうか。
プロバイダに損害賠償請求ができる場合

1:他人の権利を侵害した情報が不特定多数の者に送信されるのを防止することが技術的に可能にもかかわらず何もしなかった場合や他人の権利を侵害している情報を知っていた、または知ることができたのにもかかわらず放置していた場合
2:その情報が発信されることで、他人の権利を侵害すると確信できる理由がないにもかかわらず、投稿を発信者の承諾なしに削除した場合や、一方的に削除請求の旨を発信者に伝えずに削除した場合または、発信者から反論があるにもかかわらず投稿を削除した場合
しかし、発信者からの反論は7日以内と定められているので、7日を超えて反論した場合には、損害賠償を請求できません。
送信防止措置

削除の申立があったからといって、すぐに削除してしまうと、表現の自由に違反してしまう可能性があります。1度配信者に削除請求の旨を伝え、7日間以内に反論がない場合に削除が行われます。
削除の申立と同時に、名誉棄損や誹謗中傷等の投稿があったページを証拠として、コピーやスクリーンショットなどで保全することが重要です。
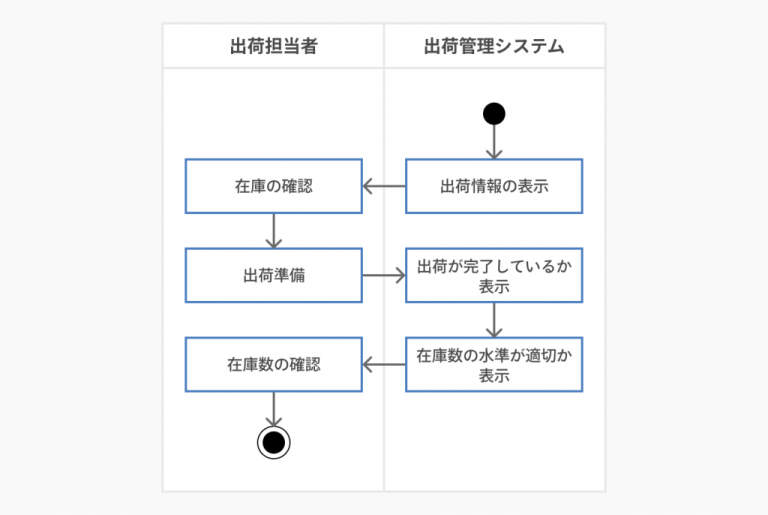
業務フロー
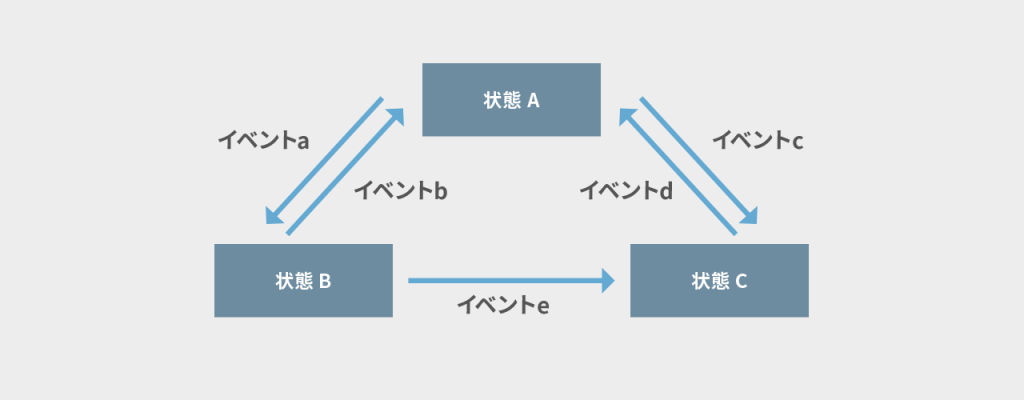
状態遷移図
アクティビティ図
アクティビティ図とはUML(統一モデリング言語)の一種で「システム実行の流れと条件分岐」を図解したものです。具体的には、ある作業の開始から終了までの機能を、実行される順序どおりに記述します。
システムの流れを記述するのがUMLですが、アクティビティ図では「実体の制御の流れ」について描写しています。実体の制御とは「どのような行動(アクティビティ)が発生するか」を指します。よってアクティビティ図はほかのUML図に比べ「どのような行動が発生するのか」を視覚的に理解しやすいです。

DX推進指標
デジタルトランスフォーメーション(DX)の変革を後押しすることを目的とし、ビジネスのアクションに繋がるための気付きの機会を提供するものとして経済産業省によって策定されたものです。項目ごとにレベル0~5の成熟度が設定されており、各企業が簡易な自己診断を行うことが可能となっています。
データ活用
データを、リアルタイム等使いたい形で使えるITシステムとなっているか
スピード・アジリティ
環境変化に迅速に対応し、求められるデリバリースピードに対応できるITシステムとなっているか
全社最適
部門を超えてデータを活用し、バリューチェーンワイドで顧客視点での価値創出ができるよう、システム間を連携させるなどにより、全社最適を踏まえたITシステムとなっているか